
以下の文章は、北岡泰典のメルマガ「旧編 新・これが本物の NLP だ!」第 80 号 (2007.12.10 刊) からの抜粋引用です。
* * * * * * *
今回は、私のある興味深い NLP 関連の発見の情報を中心にお伝えします。
1. 「左脳」と「右脳」の使い分けのモデリング
本メルマガの先号で、私は、「右脳的な体験をどんどん左脳的に説明する傾向がある一方で、(意識を、無意識的パーツを統合するオーケストラの指揮者のように機能させつつ) 左脳的なコントロールを右脳的な無意識に明け渡す」ことが真の NLP ワークであると指摘し、左脳と右脳の本来の機能分担について示唆しましたが、その後、このことに関連して、私は、「左脳と右脳の使い分け」について、ある興味深い「発見」をしました。
通常、左脳と右脳の効率的、効果的な使い分けのし方は明示化 (モデリング) されていませんが、ある私の閃きによると、この「右脳/左脳」の対比は、私の下記のお気に入りの比喩の「各駅の周辺地域のフィールドワーク/地下鉄の駅の地上レベルでのネットワークの全体像」の対比とパラレルであることがわかりました。
「NLP 個人編集演習テクニックを実際に体験することによって、NLP が単なる頭の体操的な、左脳志向の理論群ではなくて、実際には、[個人編集演習の] モデルのすべてが互いに有機的に、ダイナミックに、そしてホーリスティックに (全体的に) 関連し合っていることが体感としてわかるようになります。この時点で初めて『NLP の体系としての全体像』が見えるようになるのであり、さらに、なぜこれらのモデルがそもそも NLP 体系に導入されるようになったのかの理由もわかるようになります。比喩を使って言うと、NLP の各モデルは、大都市の地下鉄の各駅とその周辺地域のようなものですが、各駅の周辺地域をフィールドワークとして実際に現地で検証し、駅と駅を結び付けている『地上部分』を歩き回れば回るほど、ある駅と他の駅が地上ではどのように『有機的に』つながっているのかがますます実証的に認識できるようになり、最後には、地下鉄の駅の地上レベルでのネットワークの全体像が見えるようにもなります。同じことが、NLP のモデルについても言えます。」 (本メルマガ第 6 号より引用)
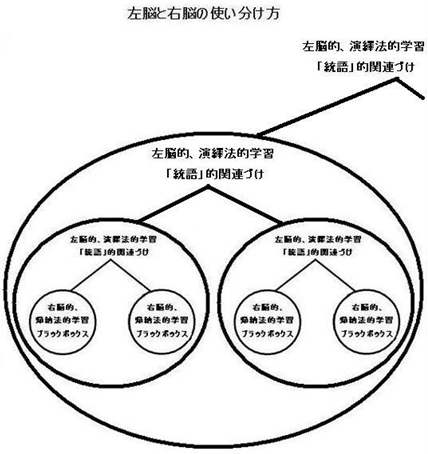
すなわち、コンテンツそのものの学習は、右脳的に、「無意識的無能性」から「無意識的有能性」まで上達するまで、試行錯誤的な反復学習を繰り返す必要がある一方で、いったん、そのコンテンツ自体が無意識化 (自動化) されれば、それを (コンテンツ フリーの) 「ブラックボックス」と見なして、あるブラックボックスと別のブラックボックスを「統語」的に関連づけることができるようになります。(このとき関連づけられるブラックボックスの数は、二つとはかぎらず、最高 7 ± 2 まで可能です。) この「統語的関連づけ」は、左脳的、演繹的作業です。
ここで注意すべきことは、まず左脳的、演繹法的関連作業をまず行った後に、ブラックスボックスのコンテンツを右脳的に、帰納法的に学習 (無意識化) することは、あそらく不可能ではないにしても、極めて非効率的であるという点です。これは、左脳的「統語的関連づけ」をする対象が、コンピュータで保存したファイルをオープンする場合と同様、コンテンツが「最終化」されて、「ぶれない」状態になっていないと、その中身を「整備」する右脳的作業に注意を向ける必要が出てきて、 あるブラックボックスを別のブラックボックスに関連づける (コンテント フリーの) プロセスとしての左脳的作業に注意を向けることができなくなるからです。
この左脳的関連づけ作業が完了すると、関連づけられた複数のブラックボックスをもう一つのさらに大きなブラックボックスとして「最終化」することができます。この最終化にも、右脳的な「無意識的無能性」から「無意識的有能性」まで上達するまで、試行錯誤的な反復作業が行われる必要があります。
この大ブラックボックスは他の (大または小) ブラックボックスと統語的に関連づけることが可能で、このことで、このフラクタル (= 入れ子) 的なプロセスを、順次再起的に拡張していくことが可能になります。
以上のことを図式化すると、以下のようになります。 (同じ図式が以下にもアップロードされています。
http://www.creativity.co.uk/creativity/jp/magazine/images/right_left.jpg )
このことを具体的に例を挙げて説明するために、私の著書『5文型とNLPで英語はどんどん上達する!』から以下の引用をしたいと思います。(67 ページ参照。ただし、以下の引用は同書の草稿段階のテキストに基づいています。)
「ここで興味深いことは、一つのチャンクとして単語にアクセスすることは、コンピュータのデスクトップでショートカットアイコンをクリックして、たとえばWordのファイルを立ち上げるようなものです。
この場合、そのWordのファイルに一つのアルファベット文字からなる単語がある場合でも、20以上のアルファベット文字からなる単語がある場合でも、その文字群を引き出すための作業は、常に一つのショートカットアイコンをクリックするというまったくの単純作業です。
このように、一番下のチャンクダウンのレベルで何も意識的に考えずに正しい単語のスペルができるように自動化されていれば、そこから一つチャンクアップして、単語Aと単語Bの組み合わせだけに全意識を集中することができるようになります。
この『句(または熟語)』レベルでは、たとえば『at school』(チャンク数は二つです)は『授業中』を意味して、『at the school』(チャンク数は三つです)というふうに定冠詞がつけば『校舎で』と、場所を表す違いがあることを学習することができます(この際、『school』の単語のスペルがあっているかどうかに神経がいくようであれば、二つまたは三つのチャンクとしてこれらの句を処理することはできません)。
この句レベルで『at school(授業中)』は『X』、『at the school(校舎で)』は『Y』であるというふうに『袋化』(「チャンク化」)して自動化できれば、その句自体が一つのチャンクとなります。そうすれば、もう一つチャンクレベルをあがって、『I am X』(すなわち『I am at school』)は『私は授業中です』であり、『I am Y』(すなわち『I am at the school』)は『私は学校の校舎にいます』である、といった節レベルの操作も可能になります。
この際、『at school』と『at the school』の違いは何であったかに対して神経が注がれるようでは、これらの節がもつ意味の違いをうまく処理することはできません。
節レベルで公式を前にして、自動的なチャンク化された詳細としての単語、句を当てはめることができるようになれば、次のレベルとして、『I was at school when an earthquake happened』(『地震が起こったとき、私は授業中だった』)と『I was at the school when an earthquake happened』(『地震が起こったとき、私は校舎にいた』)といった主節と従属節が組み合わさった完全な文の違いの理解もたやすくなります。
このように、まず、最下位のチャンクレベルの単語の自動的なチャンク化をした後、句レベルでのチャンク化、節レベルでのチャンク化ができるようになれば、次に、さまざまなレベルでのチャンクを自由自在に組み合わせられるようにもなります。
このことで、正しい英語の表現力が飛躍的に伸びます。」
以上のことについて、興味深い指摘点が二つあります。
一点目は、グレゴリー ベイツンが言及していたことに関連しています。
ベイツンによれば、(たしか聖書の一説からの引用だったと理解していますが) 「右手が行っていることは、左手が行っていることに干渉してはならない」という原則が存在します。
ここでのこの原則の意味合いは、左脳的演繹法的作業を行うべきときに右脳的帰納法的作業を混じらせてはならず、左脳の行っていることに右脳が介入すべきではないということです。もちろん、右脳の行っていることに左脳が介入すべきでもありません。
この各脳の分担機能の不適切で不必要な介入が、一部の学習困難を引き起こしているように、私には思えます。
二点目に指摘すべきことは、この左脳的機能と右脳的機能を使い分けている「人」はいったい誰かという、非常に興味深い認識論的考察点です。
私の見るところ、この「人」は、NLP の「メタ」に匹敵する「観照者 (観察者、ウィットネス)」で、この観照者は、たとえば、「現在意識 (4Te)」と「過去意識 (4Ti)」、あるいは「当事者意識 (アソシエーション)」と「部外者意識 (ディソシエーション)」を切り替えることもできます。
私の 40 年以上にわたる変性意識の研究によれば、この観照者は、ディルツの心身論理レベルの 5 つの各意識状態を「見ている人」でもあります。
ちなみに、 この左脳的機能と右脳的機能を使い分ける能力が高まると両脳を結び付けている脳梁が発達すると言われています。このことで、両脳間の情報の交換が飛躍的に拡張することは言うまでもありません。
ちなみに、以上の内容について、テキストを校正していただいた方からコメントをいただきましたので、興味深かったので、そのまま引用させていただきたいと思いました。
「このテキストに示唆されている『右脳的帰納法的学習⇒左脳的演繹法的学習』の順序は、
1.歴史的に言えば、まず催眠が混沌の中で生まれ確立されていき(右脳的帰納法的過程)、NLPにより洗練化された(左脳的演繹法的過程)。
2.NLPが作られる過程において、まず、DTIにおいて、何もかもを取り入れる(右脳的帰納法的過程)ことをした後、ここを削る、あそこを削るなどエディティングをして公式化した(左脳的演繹法的過程)。
という上記の歴史的背景とも一致していると思いました。これらの (NLP 的学習の) 法則は、言語学的にも数学的にも共通したメタ法則ということなのでしょうね。
グリンダー氏はNLPで一番重要なものはモデリングであると言っていますが、『右脳的帰納法的学習⇒左脳的演繹法的学習=NLP的モデリング』ということなのかもしれませんね。
さらに、北岡先生が指摘されているように、『メタ=観照者=観察者=ウィットネス』が最上位概念で、その次に来る重要概念が『右脳的帰納法的学習⇒左脳的演繹法的学習=NLP的モデリング』ということなのでしょう。」
作成 2023/12/16




{kind=link}