
以下の文章は、北岡泰典のメルマガ「旧編 これが本物の NLP だ!」第 5 号 (2003.11.28 刊) からの抜粋引用です。
* * * * * * *
今回のトピックに入る前に、まず 2 つのことについて語りたいと思います。
一つ目は、1995 年頃、私は英国ロンドン市で開催された NLP 共同創始者のジョン グリンダー氏の 1 日間レクチャーに参加ましたが、同氏はその冒頭で以下のようなことをおっしゃっていました (これは、同氏のレクチャー内容の逐語的転記ではありません)。
「今から約 20 年前に、私とリチャード バンドラーが、様々な帰納法的なワーク [著者注: これは、たとえば、ビデオを何度も見直して膨大な『生のデータ』から偉大なセラピストの行動/思考パターンという『公式』を見出したという意味です] の末 NLP というまったく新しい体系を作り出し、現在、幸いなことに NLP は、教育、セラピー、ビジネス、プレゼンテーション、スポーツ、芸術、司法など社会の数多くの分野にすでに浸透していて、今後ともほぼ全分野に深く行き渡っていくであろうことは、共同創始者の私としても嬉しいかぎりです。ただ、私の見るところ、20 年前に私とバンドラーが NLP を創始した後、どうも『NLP の (他の分野への) 適用』というものだけが存在してきているようで、私は個人的には、20 年前の私とバンドラーが行ったような努力をして、新しいものをクリエートする NLP 実践者が新たに出てこないかぎり、NLP は今後徐々に衰退していって、20 年~30 年後にはやがては消滅してしまう可能性があると思っています。」
私は、このグリンダー氏の立場は、「自分自身の師匠を超えることのできない弟子は『できの悪い弟子』である」と言ったとされるレオナルド ダヴィンチの立場に近いと思います。もちろん、この立場は、だからと言って、たとえば、NLP の体系全体が見えないまま、部分的 NLP 理解を基に自分自身で勝手気ままに新しい自分独自の NLP 理論、原則を作り出してもよい、ということを意味しないことは自明です。
二つ目は、私は、米国カリフォルニア州サンタ クルーズ市にある、NLP 共同開発者のロバート ディルツとジュディス ディロージャ主催の NLP ユニバーシティの公認マニュアル マテリアルの使用を許可された認定トレーナー 21 名の一人ですが、この使用許可には「教えるコースのマニュアル内容の 50% はトレーナー独自のものであること」という条件が付けられています。NLP ユニバーシティは、その意味で、NLP 実践者に、他の既存のトレーナーから学んだことを鸚鵡のように丸ごと反復するのではなく、自分自身で考えて、クリエートしていく方向性を推進しようとしていることが読み取れます。ただ、ここでも、クリエートしていくためには、必要最小限の条件としてまず基本を完全マスターしておく必要があることが含蓄されていることはいうまでもありません。
最近、私はある人から、「NLP コース受講生の中には、純粋に NLP クラシックの理論、テクニックだけを学びたいと思っている人もいる」ということを聞きました。このような受講生に、たとえば NLP 創始当時の約 30 年前の NLP テクニックだけを教えるということは愚行に近いと思われる一方で、トレーナーとして、「NLP クラシック」としての大原則、基本的理論を完全習得した後でクリエイティブな「進化した NLP テクニック」をその方々に教えることは、彼らの求めているものと何ら矛盾しないと、私は考えています。
以上のことを前提にして、以下、NLP テクニックを私なりに進化させた『北岡式学習加速法』について述べてみたいと思います。特にフラクタルという NLP 外のコンセプトから学習を考察した点が、私独自の考え方であると言えます。この方法論はまだ NLP クラシックとは呼べないかもしれませんが、今後、そのような形で NLP 体系に組み込まれていくことを願っています。
1. 学習の定義
「学習」は、「試行錯誤を通じて意識的に確立された特定の心身上の習慣を無意識的、自動的にするプロセス」と定義することができます。(ところで、ここで言う「習慣」は、重要 NLP 用語の一つである「TOTE」のプロセスと同一視できることに留意してください。)
学習の美点は、いったん私たちがあることを学んだら、その後は、同じ試行錯誤をもはや繰り返す必要がなくなる点にあります。
『精神の生態学』でグレゴリー ベイツンは、「論理タイプの理論」を使って、「学習の学び方」、「学習の学び方の学び方」といった異なるレベルの学習を論じています。
興味深いことに、低いレベルで学習で大きな進歩を果たすことは、まったく努力が不必要ではないにしても比較的に容易である一方で、高いレベルで極微の学習進歩を果たすことは極めて難しいことであるように思われます。たとえば、初心者のテニス プレーヤーが飛躍的な学習進歩 (たとえば、学習全体の比率で言って、0% から 60% までの進歩) を遂げるために必要な量と同じ量の努力とエネルギーが、その人がトップのテニス プレーヤーになる (たとえば、99% から 99.9% までの進歩) ために必要になるようにも思われます。学習レベルのこの相関関係は、後述の非常に興味深い現代的なコンセプトの「フラクタル」の観点から説明することもできます。
私自身の経験では、上記のような学習初心者にも上級者にも、同じ NLP テクニックが学習加速の効果を発揮することが確認されています。(このことは、「フラクタル」のセクションで詳述します。)
ちなみに、最も偉大なフォーミュラ ワン レーサーの一人であった故アイルトン セナは、サーキットのコーナーに入るとき常に、自分が過去に学んだドライビング プロセス (プログラミング) のうち、その特定のコーナーに最も合っているように見えるプロセスを自動的に立ち上げることができたという意味で、非常に偉大であったが、実は、すでに立ち上がった自動的プロセス (プログラミング) がなんらかの理由で充分適切に機能していないことを発見するたびに、コーナリングの真最中に、直ちにそのプロセスを意識的に停止させた上でそのコーナーにさらに適した他の学習済みのプロセスに切り替えることができたという意味で、さらに偉大であった、と言われたことがあります。
2. チャンク
チャンクは NLP の重要な概念で、私たちのバイオコンピュータが完全なグループとして処理することができる情報の最小単位です。それは、それ自身の中にもいくつかの情報を含むことができる 1 つの袋のようなものです。以下に、チャンクの説明図が示されています。
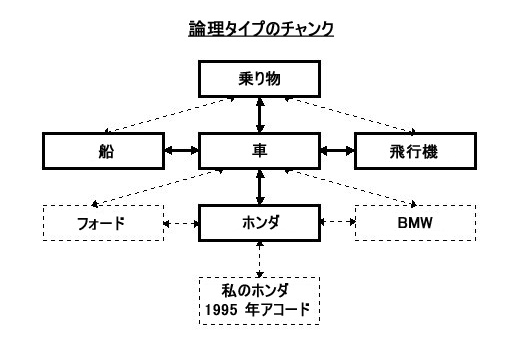
また、人間の脳は、1 時に 7 プラス マイナス 2 (すなわち 5 ~ 9) のチャンクを処理することができると言われます。このことは、仮に処理する必要がある情報数が多すぎる場合は、これらの情報を、各々 5 つから 9 つまでの情報 (チャンク) を含む、5 つから 9 つまでのグループに再編成することによって、それらの情報を処理することがしやすくなることを意味します。これにより、私たちは 25 (5 x 5) から 81 (9 x 9) 個の情報を比較的容易に処理できることになります。さらに、仮にさらに低い論理レベルにさらなる副チャンクを作る場合 (このプロセスは「チャンクダウン」と呼ばれます)、私たちは、125 (5 x 5 x 5)、729 (9 x 9 x 9) 等の数の情報を比較的苦労なしに処理することが可能になるかもしれません。
チャンクの概念は、NLP クラシックと言えますが、一つ私自身が非常に興味深いと思う事実は、各チャンクに 7 つのサブチャンクを含めながら、7 回チャンクダウンするだけで、私たちはすでに 823,543 (7 の 7 乗) 個の情報を比較的簡単に処理できるであろうということです。
このように考えると、いわゆる天才と言われている人々は、「該当の技能の学習過程で、これらのチャンクの整理、再編成が得意な人々であるだけ」のようにも思えます。言い換えれば、天才は、数個の選択肢から 1 つを選ぶプロセスを体系的に数回繰り返すことで、極めて洗練されたパフォーマンスのように見える内容を提示しているだけの人、と定義できるかもしれません。このため、これらの天才が行っていることは、各チャンキング レベルでは比較的簡単なタスクである一方で、彼らは、数の限られた適切なチャンクから数の限られた適切な情報を体系的に、首尾一貫して選択できるので (この作業自体もそれほど複雑ではないはずです)、天才たりえているのです。この単純なパターンが非常に複雑な、洗練されたパターンを生み出すメカニズムは、後述の「フラクタル」のプロセスと非常に似ています。
また、人々は通常、「林」 (パターンまたは「チャンクアップ」) を処理することだけに得意であるか、または「木」 (詳細または「チャンクダウン」) を処理することだけに得意であるかのいずれかですが、真に「ホーリスティックな」 (全体論的な) 人々は一般的に、これら両方のレベルで行うことのバランスを取ることができる人たちであるとも結論付けることができます。このバランスの確保は、思うほど困難なことではないはずです、というのも両方のレベルで行う必要があることは同じ単純な処理であるからです。
ちなみに、この点に関連して言うと、たとえば、私は NLP の方法論の観点からいかに語学学習を加速化できるかについて語ることができますが (このトピックについては次号以降で詳細に触れられます)、上記のチャンクアップとチャンクダウンのバランスを取るということは、英語のような外国語の場合では、単語のレベルから上に上るチャンクアップと構文 (主語+動詞、主語+動詞+目的語等の五文型) から下に下がるチャンクダウンの両方の意識のベクトルを常にもっていることを意味することになります。私の場合、いついかなるときでも、このチャンクアップとチャンクダウンの両方のベクトルがぶつかりあうインターフェイス上で初めて英語を理解 (聞いたり、話したり、読んだり、書いたりする) しています。現在までの国内の語学に関する学校教育法を見てみると、チャンクアップ、すなわち単語学習のみに焦点が合わされているようです。確かに、チャンクダウンの方向の統語についても語学学習の初期の頃独立のトピックとして教えられますが、複数の単語を有機的に結びつけるためには常にリアルタイムで同時進行的にチャンクダウンの統語的認識をしていなければまともな文章を書くことも喋ることもできないという『コロンブスの卵』的な事実が強調されることは教育の現場でまずないようですし、また、そのようなチャンクダウンの意識を継続的にもてるような訓練を語学学習者にさせるなどということは現状では想像さえできないことです。
3. フラクタル
フラクタル デザインは、単純な式に基づいた演算を行うことにより生成されます。演算の結果を同じ式に再入力しながら、このプロセスが何度も反復されます。フラクタル図の 1 例が以下に示されています。
Copyright (c) 1997 Cygnus Software. All rights reserved.
このイメージは、フラクタル イメージ生成ソフトの Fractal eXtreme (TM)
で生成され、Cygnus Software の許可により複製されています。
Fractal eXtreme (TM) は、以下のアドレスからダウンロード可能です。
http://www.cygnus-software.com
フラクタル パターンは、銀河、ハリケーン、リアス式海岸、山、川、木、カリフラワー、静脈等のような自然の事物の形成方法を象徴していると言われています。その特徴は、全体論的、非線形、回帰的です。
フラクタルのモデルを使うと、普遍的な生命形態の問題に対する解決を提示する可能性もあるかもしれません。たとえば、重要であるが、かなり誤解されていた精神分析学者のウィルヘルム ライヒがかつて普遍的な生命形態を特定しようとして提示した単純なペイズリー状の形態よりもいっそう説得力があるように思われます。
学習加速化の観点から見ると、フラクタルのコンセプトによって、なぜ短時間で容易に学ぶことが可能できる人がいる一方で、学習速度が遅い人もいるのかの原因を解明できるかもしれず、また、学習プロセスを加速することにおいて支援になるかもしれないという点において、フラクタル モデルは大きな意味合いと可能性をもっています。
たとえば、上記で、0% から 60% までの学習進歩を遂げる初心者のテニス プレーヤーと 99% から 99.9% までの進歩を遂げるトップのテニス プレーヤーに関して、両者とも同じ量の努力とエネルギーが必要かもしれないと示唆されましたが、このことは、以下のフラクタル図を見ると、比喩的に理解ができます。
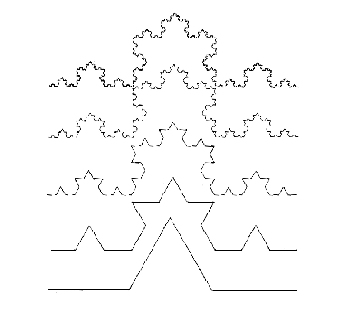
すなわち、この図の一番下のレベルでは、一回の処理で非常に大きな (粗野な) 変化を達成することができますが、一番上のレベルでは同じフラクタル処理をしてもごく小さな (極微の) 変化しか達成できません。
また、この際、この図の各レベルにおける変化は規模は違っても、風船を膨らませたときに始めに風船上に書いていた字がそのまま同じまま大きくなっていくように、パターン自体はまったく変わらずにいます。このことは、同じ基礎パターン、すなわち、同じ基本的なテニスのラケットの振り方が、初心者のレベルでも上級者のレベルでも、同じように繰り返される必要があることがわかります。
通常は、人々は、上級学習者は他の人々には達成不可能なような非常に複雑なことを学習、達成していると思いがちですが、上記の観点から見ると、非常に簡単な一定数の (おそらくは 5~9 つの) 基本的テクニックを完全マスターし、それらのパターンをただ忠実に反復しているにすぎないであろうことがよくわかります。
なぜ、このような上級者が反復している基本的テクニックがアウトサイダーには非常に複雑に見えるかは、上述の「チャンク」のコンセプトと組み合わせて考えるとよく説明できます。
すなわち、たとえば 7 つの基本テクニックを完全習得した学習者は、その 7 つのテクニックの一つを他の一つのテクニックと組み合わせ、その結果生み出された「新しい」学習パターンに、再び 7 つのテクニックのうちの一つを組み合わせるという単純な作業をたった 7 回反復するだけで実に 823,543 (7 の 7 乗) 通りの学習パターンを達成することができるようになります。(仮に、ここで「達成することができる」という断定的表現に語弊があるようであれば、「823,543 (7 の 7 乗) 通りの学習パターンを達成できる柔軟性を獲得することができるようになります」と言い換えることができます。)
このように、「チャンク」と「フラクタル」のモデルを組み合わせることで、「学習の学び方の学び方 (How to Learn to Learn to Learn)」とその学習過程を飛躍的に加速化するメカニズムの解明が可能になり、また実際にどのような学習態度で臨めば自分の学習過程の加速化が計れるかが非常に明確になります。
著者追記: おかげさまで先週週末に私自身の国内第 1 期 NLP プラクティショナー資格認定コースが始まりました。このメルマガの紙上を借りて、私は同コース受講者の方々全員の、 NLP を真剣に、真摯に、そして左脳 (知的理解) と右脳 (英語で言う「スキン メモリー」の体感理解) の両方でホーリスティックに学習、習得しようとするコミットメントの強さを感じ、参加者の方々と私自身の非常に有意義な相互学習の場がもてたことを、非常にうれしく思っていることをお伝えしたいと思いました。コース受講者の皆さんの非言語的反応を見るかぎり、私の伝えていることに対する理解度が高そうだったので、各トピックの左脳的説明を「必要以上」に掘り下げて行った場合もときどきあったほどでしたが、このような形で、私が NLP のルーツに一番近いと信じている形で、いわば「口頭伝授」的に、国内の方々に実地の場で、NLP の理論と哲学を体系的に伝え、NLP テクニック演習をデモ実践し始めることができるようになったことに関し、第一期コース受講生に改めてここで感謝いたします。
作成 2023/10/2



